Automating Data Science: Optimizing XGBoost Machine Learning Models with AI Agents
by Szilard Pafka and Eduardo Ariño de la Rubia
TL;DR In this project, we demonstrate that today’s AI coding agents can automate data science tasks such as feature engineering and hyperparameter optimization of machine learning models. AI agents can conduct research, acquire domain knowledge, and make informed decisions about what to try next. They can automate many of the tedious, repetitive tasks a data scientist faces when exploring hundreds of feature engineering and model tuning candidates — and evaluate what has and hasn’t worked so far to proceed accordingly. That said, this does not mean the data scientist’s role can be replaced by AI today. The data scientist remains in the driver’s seat, guiding the AI and monitoring, interpreting, and assessing the results. The AI agent is best understood as a tool that significantly augments the data scientist — automating manual work for a substantial productivity gain.
For several decades, much of the most valuable data in business has been stored in structured, tabular format. Extracting value from such data typically involves a standard data science pipeline: data preparation, training machine learning models, optimizing model parameters, and combining top-performing models. In most practical applications with tabular data, the models achieving the highest accuracy are gradient boosting machines (GBMs), with popular open-source implementations such as XGBoost or LightGBM. Building such models requires writing code for feature engineering, hyperparameter tuning, and (optionally) model ensembling.
In the past few months, AI coding agents such as Claude Code have transformed software development, with an increasing share of code now written by AI. Inspired by Andrej Karpathy’s Autoresearch project — which uses AI agents to autonomously conduct research and improve large language models (using AI to improve AI) — we created a template for AI agents to iteratively explore feature engineering transformations and XGBoost hyperparameters, yielding progressively better models on a given tabular dataset. This template (open-sourced and available on GitHub) can be readily adapted for new datasets, alternative models such as LightGBM, or model ensembling.
In the GitHub repository we also provide an end-to-end example in which we use Claude Code with our template to optimize a binary classification XGBoost model on a given dataset in two scenarios. In the first scenario, the agent optimizes the model (feature engineering and hyperparameters) using 5-fold cross-validation on a sample of 100,000 records, tracking AUC (area under the curve) as the accuracy metric. In each iteration, the AI agent proposes a new candidate model, keeping it if AUC improves and discarding it otherwise. We then track post-hoc the AUC across three evaluation settings: the “full model” retrained on the complete sample, the “4/5 model” trained on four folds (to be comparable with the cross-validation AUC scores), and a “time-separated” holdout sample using 2006 data (the model was trained on 2005 data). The results are shown below.
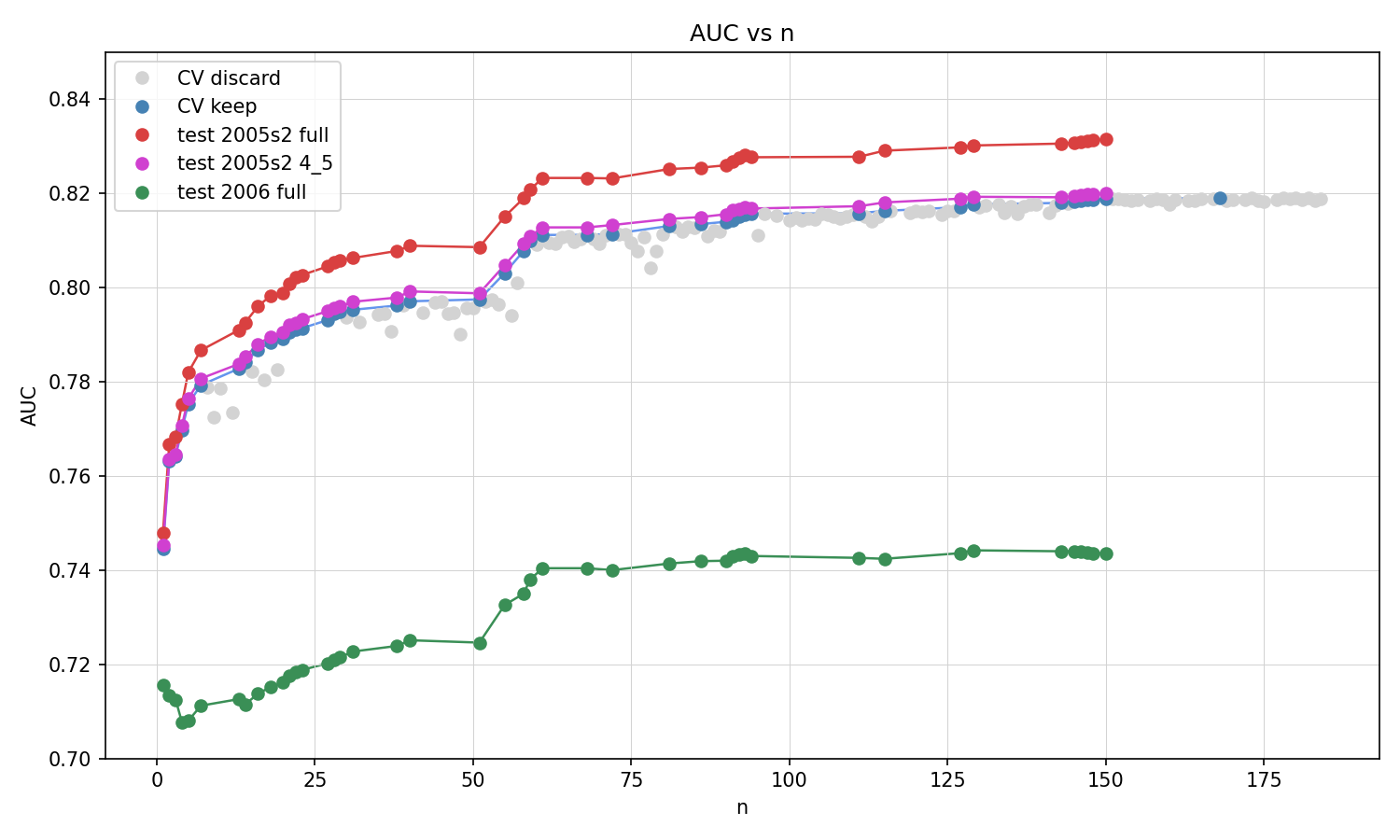
As shown, the AI agent successfully delivers models of increasing accuracy, much like a human data scientist who iteratively tries different feature engineering transformations and hyperparameter settings. Like a human data scientist, the AI agent also draws on domain knowledge — researching online resources such as machine learning competition write-ups — to make informed decisions about what to try next. The graph shows discarded models in grey (lower AUC), kept models’ CV AUC in blue, the 4/5 model AUC in magenta (matching the CV AUC), the full model AUC in red (higher, as it was trained on 25% more data than the CV models), and the time-separated holdout AUC in green (lower, reflecting distributional shift over time). The improvement across all AUC metrics demonstrates the effectiveness of our approach. Notably, these gains stem from both feature engineering and hyperparameter optimization. For example, the agent independently devises ideas such as decomposing the departure time feature into hours and minutes components and applying sine/cosine cyclical encoding — both of which improve AUC by as much as some of the best hyperparameter tweaks.
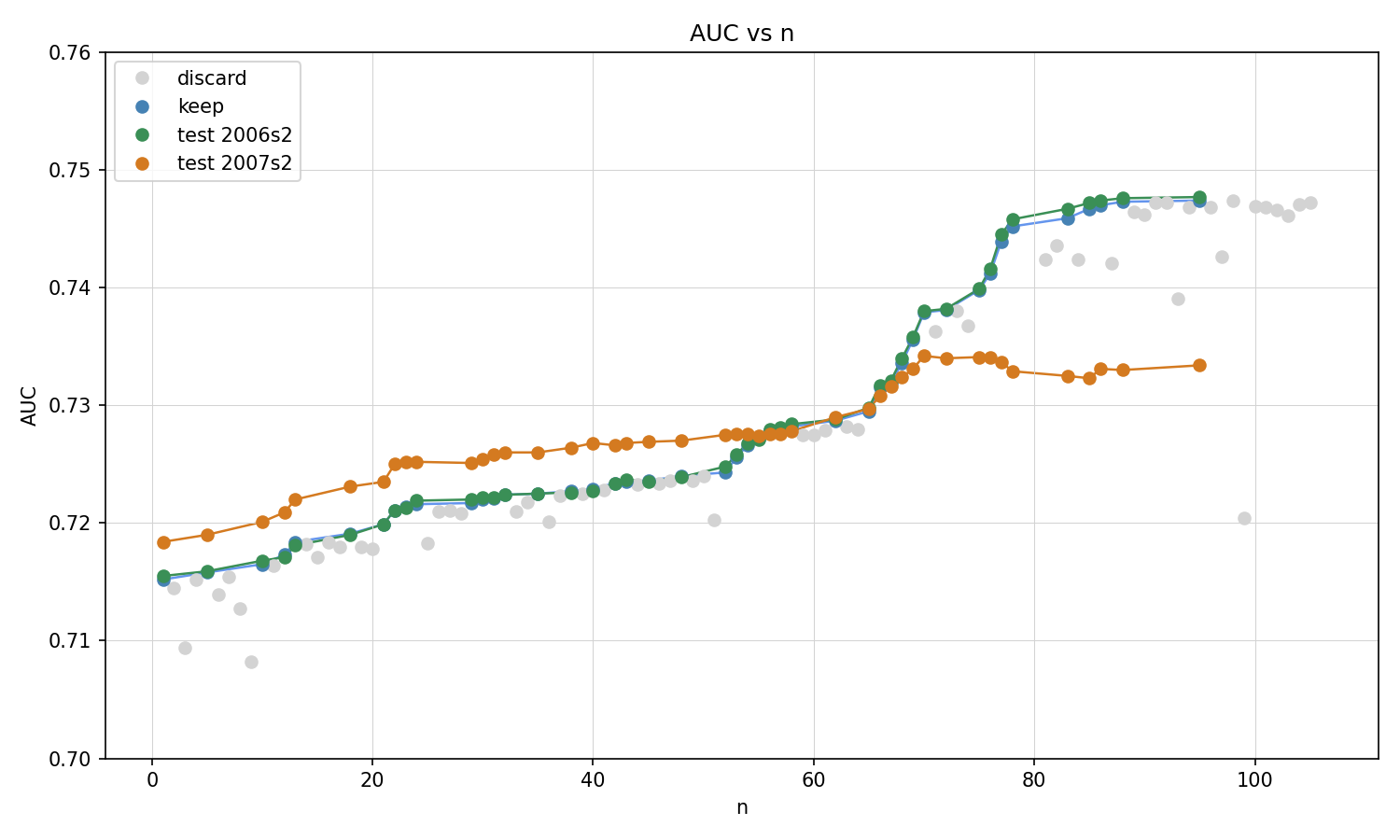
In a second scenario, the AI agent trains on 2005 data (100,000 records) but evaluates each candidate model on 2006 data (100,000 records) to decide whether to keep or discard it. We also evaluate the models post-hoc on a larger 2006 sample and on a 2007 sample. The AUC on the larger 2006 post-hoc sample closely tracks the AUC on the evaluation data used by the agent, confirming that this multi-evaluation setup does not lead to noticeable overfitting to the evaluation set. The AI agent again successfully delivers models of increasing accuracy, though improvement on the 2007 data is more modest, reflecting distributional shift over time.
In this project we have demonstrated that AI coding agents can automate data science tasks such as feature engineering and hyperparameter optimization. Such agents can research domain knowledge, make informed decisions about what to try next, evaluate what has and hasn’t worked, and iterate accordingly — automating much of the trial-and-error that would otherwise fall to a human data scientist. This does not mean the role of the data scientist can be completely substituted by AI. The data scientist remains essential: defining the problem, setting up the broader project context, driving the agent (in our case via the program.md instruction file), and monitoring and interpreting the results. Today’s AI agent is best understood as a powerful productivity tool that significantly augments the data scientist by automating manual tasks — a force multiplier, not a replacement.
License: CC BY 4.0